Chinese tech company Tencent just introduced its latest large language model, Hunyuan Turbo S, featuring significantly faster response times without sacrificing performance on complex reasoning tasks.
Tencent claims that its new AI doubles word generation speed and cuts first-word delay by 44% compared to previous models, according to official information that the Chinese tech giant shared on Weibo.
The model uses what appears to be a hybrid architecture combining Mamba and Transformer technologies—the first successful integration of these approaches in a super-large Mixture of Experts (MoE) model.
This technical fusion aims to solve fundamental problems that have plagued AI development: Mamba handles long sequences efficiently while Transformer captures complex contexts, potentially lowering both training and inference costs. Being hybrid means that the model combines reasoning capabilities with the traditional approach of normal LLMs that provide immediate response.
“The combination and complement of fast thinking and slow thinking can make large models solve problems more intelligently and efficiently,” Tencent wrote when announcing the model on its official WeChat channel. The company drew inspiration from human cognitive processes, designing Hunyuan Turbo S to provide instant responses like human intuition while maintaining the analytical reasoning capabilities needed for complex problems.
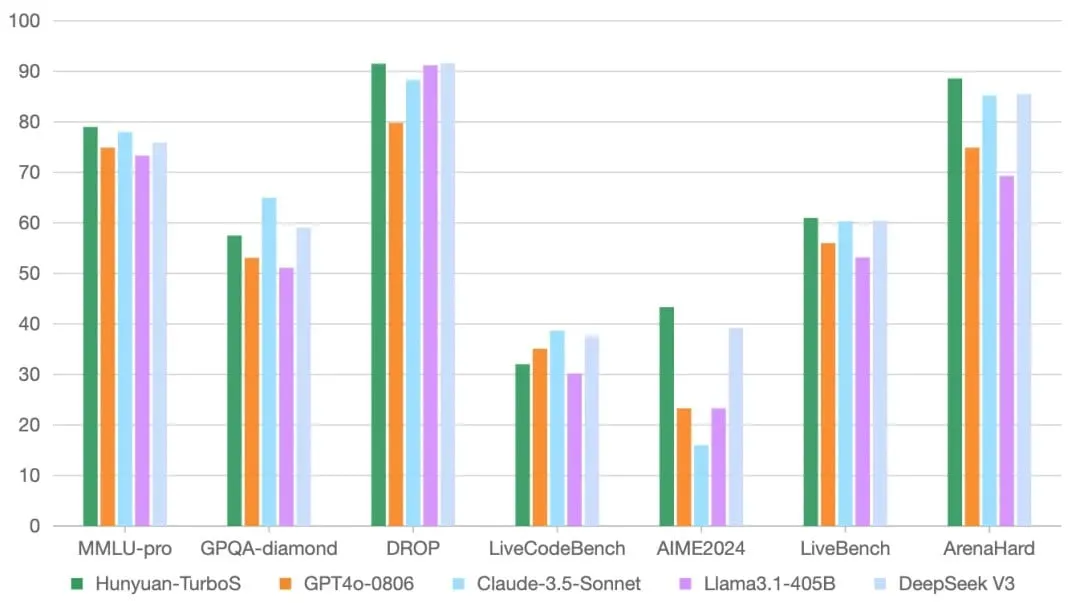
Performance benchmarks show Hunyuan Turbo S matching or exceeding top-tier models across various tests. It scored 89.5 on MMLU, slightly above OpenAI’s GPT-4o, and achieved top scores in mathematical reasoning benchmarks MATH and AIME2024. For Chinese language tasks, it reached 70.8 on Chinese-SimpleQA, outperforming DeepSeek’s 68.0. However, it lagged in some areas like SimpleQA and LiveCodeBench, where GPT-4o and Claude 3.5 performed better.
The release intensifies the ongoing AI competition between Chinese and American tech firms. DeepSeek, a Chinese startup that has gained attention for its cost-effective, high-performing models, has been putting pressure on both Chinese tech giants and American companies like OpenAI with its highly capable and ultra efficient models.
DeepSeek’s models reportedly cost around $6 million to train and are extremely cheap to run, charging around $1.10 per million tokens of output vs OpenAI’s GPT-4.5 and its wildly expensive $150 per million output tokens.
Tencent priced Hunyuan Turbo S competitively at 0.8 yuan (approximately $0.11) per million tokens for input and 2 yuan ($0.28) per million tokens for output—significantly cheaper than previous Turbo models. The model is technically available via API on Tencent Cloud, with the company offering a free one-week trial, but it is still not available for public download.
Despite the announcement, Hunyuan Turbo S isn’t yet widely accessible for download, but can be accessed via the Tencent Ingot Experience site. Interested developers and businesses need to join a waiting list through Tencent Cloud to gain access to the model’s API. The company hasn’t provided a timeline for general availability via Github.
The model’s focus on speed could make it ideal for real-time applications like virtual assistants and customer service bots—areas that are very popular in China and in which Hunyuan Turbo S could offer significant advantages if it delivers on its promised capabilities.
Chinese competition in the AI space continues to heat up, with the government pushing for more adoption of local models. Beyond Tencent, Alibaba recently introduced its latest state-of-the-art model Qwen 2.5 Max, and startups like DeepSeek have released increasingly capable models in recent months.
Edited by Andrew Hayward
Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.





Leave a Comment