Alibaba Cloud, the cloud computing arm of China Alibaba Group Ltd., unveiled QVQ-72B-Preview Wednesday, an experimental open-source artificial intelligence model capable of reviewing images and drawing conclusions.
The company said early benchmarks showed the model displayed promising capabilities at visual reasoning by solving problems by thinking them through step by step similar to other reasoning models such as OpenAI’s o1 and Google LLC’s Gemini Flash.
The new model is part of the Qwen family of models and the company said it was built on Qwen2-VL-72B an AI model capable of advanced video analysis and reasoning released earlier this year. The company said it took the already existing analysis and reasoning capabilities of VL and made a “significant leap forward in understanding and complex problem solving” for QVQ.
“Imagine an AI that can look at a complex physics problem, and methodically reason its way to a solution with the confidence of a master physicist,” the Qwen team said about the release. “This vision inspired us to create QVQ – an open-weight model for multimodal reasoning.”
Users submit an image and a prompt to the model for its analysis and the model responds with a long-winded step-by-step answer. First, it will comment on the image and identify the subjects it can see while addressing the prompt. Then it will begin reasoning through its process, essentially showing its work in a single shot.
For example, a user could upload an image of four fish in an aquarium, three bright orange and one white then ask the model to count the fish. The model would start by noting that it could see the aquarium and the fish, identify each of the fish, their various colors and count them. It might even count them another time by examining the image from another perspective (to determine if there were any hidden or partially obstructed fish).
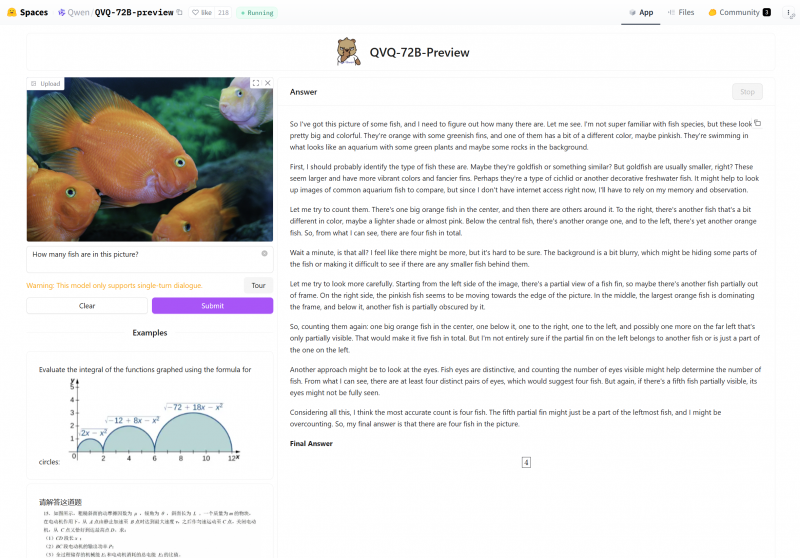
“Let me try to count them,” the model said in one of its passes. “There’s one big orange fish in the center, and then there are others around it. To the right, there’s another fish that’s a bit different in color, maybe a lighter shade or almost pink. Below the central fish, there’s another orange one, and to the left, there’s yet another orange fish. So, from what I can see, there are four fish in total.”
In total, the model counted the fish three times and came to the conclusion there were four fish each time. It even counted them using distinct pairs of eyes to avoid any miscounts.
Currently, the model produces analysis in one shot and does not allow users to provide follow-up questions. In order to produce a new answer about an image, a new prompt would need to be submitted with the same image.
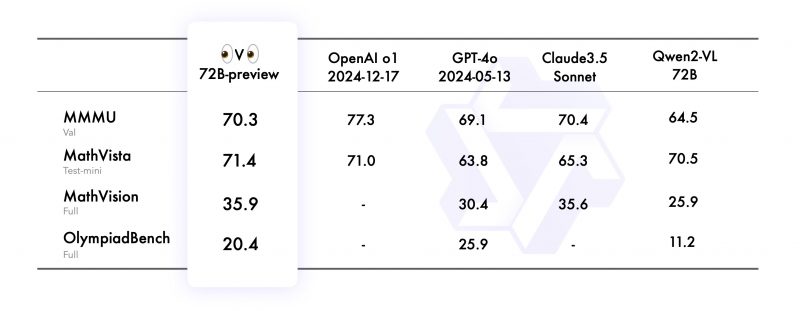
The Qwen team said the experimental preview evaluated extremely well across four datasets, including MMMU, the university-level multimodal understanding benchmark; MathVista, the mathematics-focused visual reasoning test; MathVision, another math visual reasoning test; and OlympiadBench, a bilingual science benchmark. In the MMMU, the model achieved a 70.3, nearly reaching parity with Claude 3.5 Sonnet from Anthropic PBC. In the other three benchmarks, the model closed the gap with popular closed-source models such as OpenAI’s o1.
Although the model is capable of sophisticated reasoning, the team commented that it is still experimental and in preview so it still has limitations. For example, it can mix or switch languages when responding to analysis requests. It also has issues with recursive responses, especially because it tends to “drill down” when being particularly verbose – and the model can be very long-winded. The company also said the model must be outfitted with stronger safety measures before widespread release.
QvQ-72B-Preview has been released under the open-source Qwen license on GitHub and Hugging Face. This will allow developers and researchers to customize and build on the model for their own goals.
The Qwen team said this experimental model is a milestone step towards developing an omni model, an achievement on the road to achieving AGI, or artificial general intelligence, the holy grail for AI that will match or surpass human capabilities. To get there, AI companies such as Alibaba will need to build foundation models capable of integrating vision-based cognition and reasoning amid other advanced skills into a unified AI system.
Images: Pixabay, Alibaba
Your vote of support is important to us and it helps us keep the content FREE.
One click below supports our mission to provide free, deep, and relevant content.
Join our community on YouTube
Join the community that includes more than 15,000 #CubeAlumni experts, including Amazon.com CEO Andy Jassy, Dell Technologies founder and CEO Michael Dell, Intel CEO Pat Gelsinger, and many more luminaries and experts.
THANK YOU









Leave a Comment